文章翻译
文章翻译

在我们日常学习中,经常会遇到不同语言的文字,我们想快速把它翻译成中文或者其他语言怎么办?今天我来教大家如何快速翻译
在线体验
视频教程
文字教程
打开智游剪辑,搜索文章翻译
我们选择目标语音和原文信息,点击开始翻译就可以自动进行翻译了
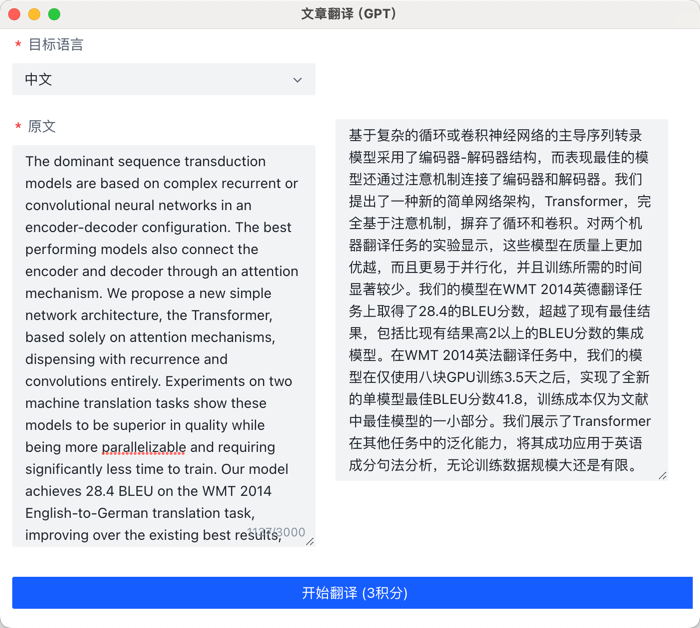
效果预览
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
基于复杂的循环或卷积神经网络的主导序列转录模型采用了编码器-解码器结构,而表现最佳的模型还通过注意机制连接了编码器和解码器。我们提出了一种新的简单网络架构,Transformer,完全基于注意机制,摒弃了循环和卷积。对两个机器翻译任务的实验显示,这些模型在质量上更加优越,而且更易于并行化,并且训练所需的时间显著较少。我们的模型在WMT 2014英德翻译任务上取得了28.4的BLEU分数,超越了现有最佳结果,包括比现有结果高2以上的BLEU分数的集成模型。在WMT 2014英法翻译任务中,我们的模型在仅使用八块GPU训练3.5天之后,实现了全新的单模型最佳BLEU分数41.8,训练成本仅为文献中最佳模型的一小部分。我们展示了Transformer在其他任务中的泛化能力,将其成功应用于英语成分句法分析,无论训练数据规模大还是有限。
主要のシーケンス変換モデルは、複雑な再帰型または畳み込みニューラルネットワークをエンコーダー-デコーダー構成で基にしています。最も優れたモデルでは、エンコーダーとデコーダーを注目メカニズムを介して接続しています。私たちは、再帰性と畳み込みを完全に廃止し、単に注目メカニズムに基づく新しいシンプルなネットワークアーキテクチャ、Transformerを提案します。2つの機械翻訳タスクでの実験により、これらのモデルがより優れた品質でありながら、より並列化が可能であり、学習にはかなり少ない時間を必要とすることが示されました。当モデルは、WMT 2014年の英独翻訳タスクにおいて28.4のBLEUを達成し、既存の最良の結果を2 BLEU以上上回ります。また、WMT 2014年の英仏翻訳タスクにおいて、当モデルは、8つのGPUで3.5日学習後に、新しい単一モデルの最先端BLEUスコア41.8を確立し、既存のモデルからの学習コストのわずかな部分に達します。Transformerは、他のタスクにもうまく適用することで、大規模および限られた学習データの両方で英語の構成解析に成功裏に適用されることを示します。
주요 시퀀스 변환 모델은 복잡한 순환 또는 합성곱 신경망을 부호화-해독기 구성으로 기반으로 합니다. 성능이 우수한 모델은 부호화기와 해독기를 주의 메커니즘을 통해 연결합니다. 우리는 순환 및 합성곱을 완전히 없앤 주의 메커니즘만을 기반으로 하는 새로운 간단한 네트워크 아키텍처, Transformer를 제안합니다. 두 가지 기계 번역 작업에 대한 실험 결과, 이러한 모델이 품질 면에서 우수하며 병렬화가 더 용이하며 훈련하는 데 상당히 적은 시간이 필요함을 보여줍니다. 저희 모델은 WMT 2014 영어-독일어 번역 작업에서 28.4 BLEU를 달성하여 기존 최고 성능을 향상시켰으며, 2 BLEU 이상의 BLEU로 구성된 것들을 포함합니다. WMT 2014 영어-프랑스어 번역 작업에서, 저희 모델은 8개의 GPU에서 3.5일 동안 훈련한 후 41.8의 BLEU 점수를 달성하여 단일 모델 최첨단 성능을 세우며, 훈련 비용이 저능되문 학술논문 모델보다 적은 일부 만을 소모합니다. Transformer가 큰지와 제한된 훈련 데이터로 영어 구성 요소 구문 분석에 성공적으로 적용함으로써 해당 모델이 다른 작업에 잘 일반화된다는 것을 보여줍니다.