文案改写助手
大约 8 分钟约 2419 字
文案改写助手

大家写文案时肯定为自己的文案不够有趣而烦恼过,或者有时候一篇文章需要按照不同的风格来写,那么有没有一款工具可以帮你在保持核心内容不变的情况下,改成文章的整体风格呢? 下面给大家介绍一下文案改写助手
在线体验
视频教程
文字教程
打开智游剪辑,搜索文案改写助手
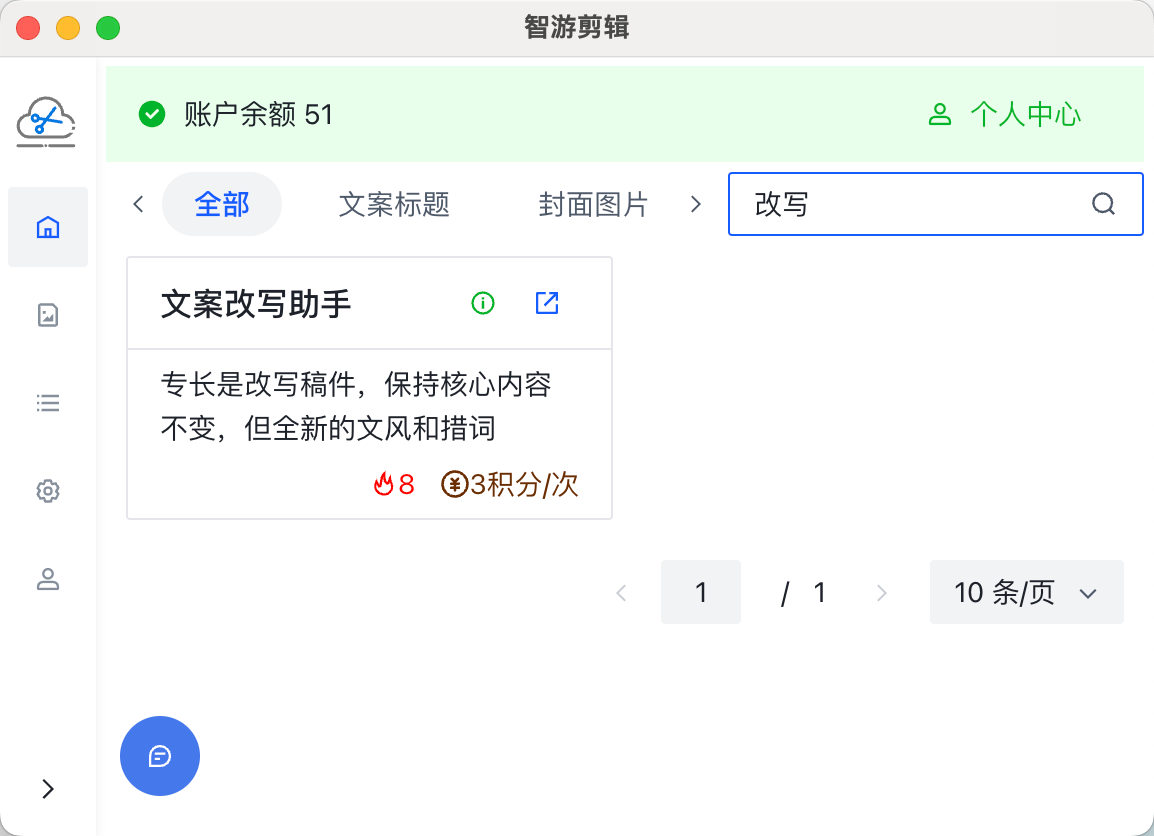
我们输入原始的文章信息,然后,选择要改写的风格,目前支持专业、娱乐、新闻、评论、故事等不同的文章风格
确认好风格后我们点击立即生成就可以了
效果预览
原文信息
只需一段文字指令就能生成一段逼真视频,今年初,文生视频大模型Sora在全球人工智能业内外引发广泛关注。27日,2024中关村论坛年会上首次发布我国自研的具“长时长、高一致性、高动态性”特点的文生视频大模型Vidu。
记者从会上获悉,这一视频大模型由清华大学联合北京生数科技有限公司共同研发,可根据文本描述直接生成长达16秒、分辨率高达1080P的高清视频内容,不仅能模拟真实物理世界,还拥有丰富想象力。
清华大学人工智能研究院副院长、生数科技首席科学家朱军说,当前国内视频大模型的生成视频时长大多为4秒左右,Vidu则可实现一次性生成16秒的视频时长。同时,视频画面能保持连贯流畅,随着镜头移动,人物和场景在时间、空间中能保持高一致性。
在动态性方面,Vidu能生成复杂的动态镜头,不再局限于简单的推、拉、移等固定镜头,而是能在一段画面里实现远景、近景、中景、特写等不同镜头的切换,包括能直接生成长镜头、追焦、转场等效果。
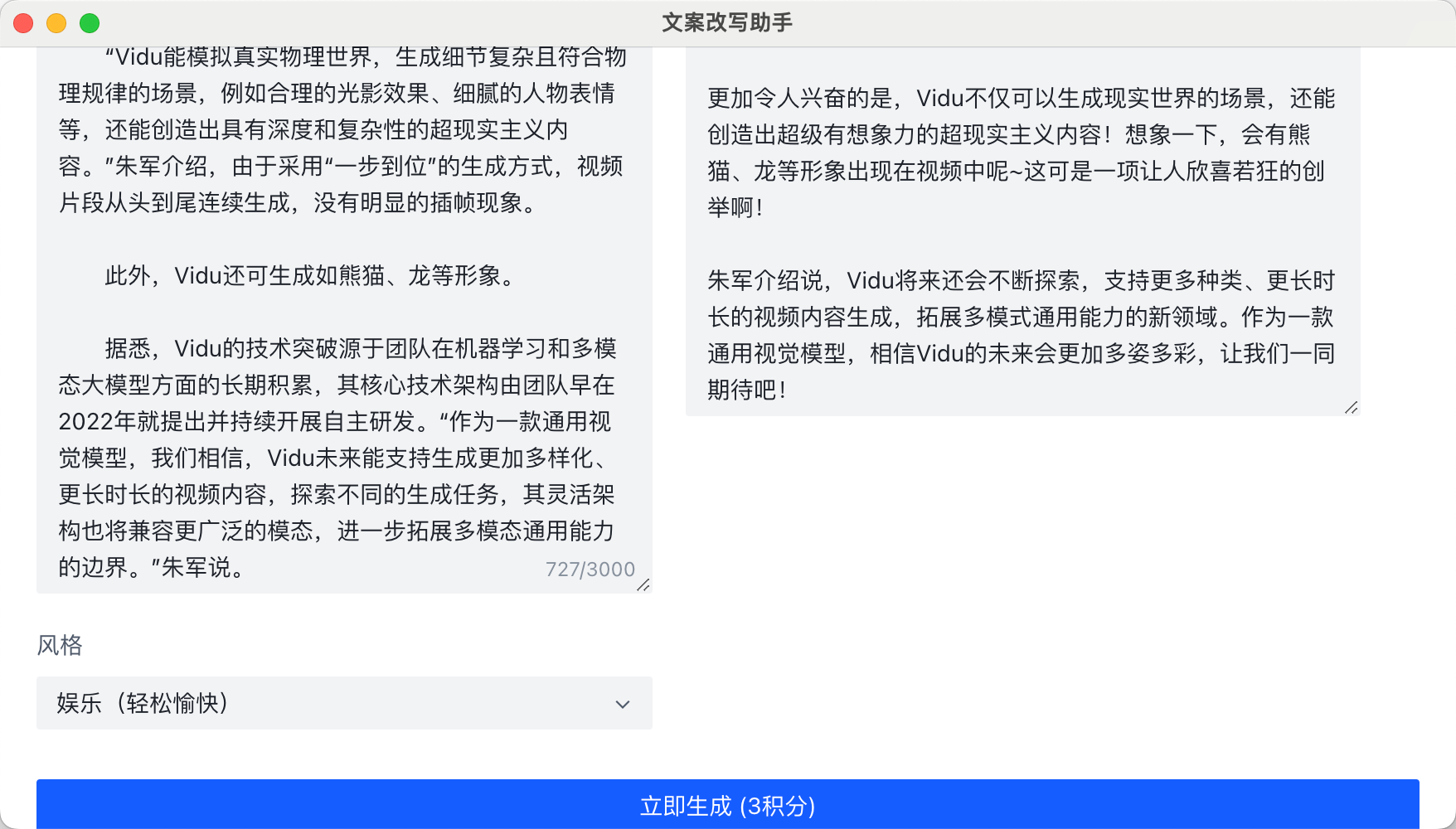
“Vidu能模拟真实物理世界,生成细节复杂且符合物理规律的场景,例如合理的光影效果、细腻的人物表情等,还能创造出具有深度和复杂性的超现实主义内容。”朱军介绍,由于采用“一步到位”的生成方式,视频片段从头到尾连续生成,没有明显的插帧现象。
此外,Vidu还可生成如熊猫、龙等形象。
据悉,Vidu的技术突破源于团队在机器学习和多模态大模型方面的长期积累,其核心技术架构由团队早在2022年就提出并持续开展自主研发。“作为一款通用视觉模型,我们相信,Vidu未来能支持生成更加多样化、更长时长的视频内容,探索不同的生成任务,其灵活架构也将兼容更广泛的模态,进一步拓展多模态通用能力的边界。”朱军说。
娱乐风格(轻松愉快)
在今年初,文生视频大模型Sora在全球人工智能行业引起了热烈讨论。就在27日的2024中关村论坛年会上,一款备受瞩目的国产文生视频大模型Vidu首次亮相啦!
听说,这个视频大模型是由清华大学联合北京生数科技有限公司联合研发的哦。它可以根据简单的文字描述,立刻生成长达16秒,分辨率高达1080P的清晰视频内容。不仅可以模拟真实世界,而且还蕴含着无限的想象力哦!
据悉,Vidu可是实现了十分厉害的技术突破呢!它可以生成复杂的动态画面,不再仅限于之前的单调推拉,而是可以在画面中切换远景、近景、中景,甚至各种不同的特写镜头哦。而且,画面流畅自然,镜头移动时人物和场景保持高度一致性,感觉好像是身临其境一样!
更加令人兴奋的是,Vidu不仅可以生成现实世界的场景,还能创造出超级有想象力的超现实主义内容!想象一下,会有熊猫、龙等形象出现在视频中呢~这可是一项让人欣喜若狂的创举啊!
朱军介绍说,Vidu将来还会不断探索,支持更多种类、更长时长的视频内容生成,拓展多模式通用能力的新领域。作为一款通用视觉模型,相信Vidu的未来会更加多姿多彩,让我们一同期待吧!
新闻风格(简洁客观)
今年初,文生视频大模型Sora引起了全球人工智能行业的关注。在2024中关村论坛年会上,我国自主研发的文生视频大模型Vidu首次发布。这一视频大模型由清华大学联合北京生数科技有限公司研发,可根据文本描述直接生成长达16秒、分辨率高达1080P的高清视频内容。清华大学人工智能研究院副院长、生数科技首席科学家朱军表示,Vidu能实现一次性生成16秒的视频时长,画面连贯流畅,保持高一致性,并具备复杂的动态镜头功能,能生成不同镜头的切换效果。朱军介绍说,Vidu能模拟真实物理世界,生成细节复杂且符合物理规律的场景,具有超现实主义内容。此外,Vidu还具备生成形象如熊猫、龙等的功能。该技术突破得益于团队在机器学习和多模态大模型方面的长期积累,其灵活架构将进一步拓展多模态通用能力的边界。
评论风格(主观论证)
今年初,文生视频大模型Sora在全球人工智能业内外引发了广泛关注。在2024中关村论坛年会上,我国自研的文生视频大模型Vidu首次发布,具备“长时长、高一致性、高动态性”特点。
这一视频大模型由清华大学与北京生数科技有限公司共同研发,能根据文本描述直接生成长达16秒、分辨率高达1080P的高清视频内容。与国内其他视频大模型相比,Vidu能一次性生成更长达16秒的视频时长,画面保持流畅连贯,并且在镜头移动时保持高一致性。
不仅如此,Vidu在动态性方面也有着显著的突破。它可以生成复杂的动态镜头,包括不同镜头的切换,追焦、转场等效果,让画面更加生动多样。
朱军介绍说,Vidu能模拟真实物理世界,生成细节复杂且符合物理规律的场景,呈现出超现实主义般的深度和复杂性内容。而且,由于采用“一步到位”的生成方式,视频片段从头到尾连续生成,没有明显的插帧现象。
除此之外,Vidu还具备生成各种形象如熊猫、龙等的能力。
这一技术突破源于团队在机器学习和多模态大模型方面的长期积累,其灵活架构将支持生成更加多样化、更长时长的视频内容,拓展多模态通用能力的边界。Vidu的发布标志着我国在人工智能领域迈出了重要一步,未来的发展潜力不容小觑。
故事风格(故事情节)
新稿:故事开始于一个风和日丽的下午,在一个充满未知和探险的幻想世界里。主角艾丽丝,一个拥有无限想象力和勇气的年轻女孩,梦想着探索文明的未来。
在这个充满神秘色彩的世界中,艾丽丝邂逅了摄影师小杰,一个身手矫捷、机智过人的年轻人,他能通过镜头记录下每一个瞬间的美好。他们一同踏上了一段奇幻之旅,探寻着隐藏在时间和空间中的秘密。
然而,他们的旅程并不一帆风顺。反派角色恶魔艾德加,一个掌控着黑暗力量的神秘人物,不断出现在两人的路上,试图阻止他们揭开真相。在一次次生死搏斗中,艾丽丝和小杰的友情与勇气得到了考验,他们共同面对内心的恐惧和挑战。
随着故事的展开,艾丽丝和小杰逐渐揭开了文明的面纱,发现了一段令人震撼的历史。他们学会了勇敢、合作和信任,共同对抗邪恶,保护美好。最终,在一场惊心动魄的决战中,他们打败了恶魔艾德加,为这个幻想世界带来了和平与希望的曙光。
通过这段奇幻史诗般的旅程,艾丽丝和小杰不仅找到了自己的价值和勇气,也为读者展现了友情、勇气和希望的珍贵意义。他们的故事将永远留存在大家的心中,激励着每个人勇敢面对挑战,追求梦想。